Last October I mentioned a board game called c-jump, with the following commentary:
I think this concept of “teaching kids to program” meaning teaching them C-like syntax is symptomatic of a deeper problem in the industry; the idea that knowing how to program means only knowing the syntax for a language, being able to put together a file about which the compiler doesn’t complain.
More recently (okay, January) I ran across a very different concept for teaching kids to program, a development environment from Carnegie Mellon called Alice that answers my objections neatly. In Alice, there's no emphasis on the syntax itself; the environment prevents you from needing to know the syntax by enforcing correctness rules (at any given time you can only make changes that result in a legal program). The point is that then you can concentrate on what you want the program to do, rather than how you get the program to do what you want.
I think this approach would be much more successful at teaching kids programming; what's really impressive is that it includes some concepts that are rarely if ever actually taught in classes (such as concurrency and event-based programming) but that can be very important in the real world.
While I'm on the subject, I read another very interesting article recently. Coding Horror linked to an academic paper about predicting which students can become successful programmers, and which can't. Apparently between 30 and 60% of incoming C/S students fail their first programming course, not because they're not smart or hardworking (although there are those, too ;)), but because they either cannot form a consistent enough mental model to understand the system, or they reject the whole exercise as nonsense. It was actually kind of a shock to me to learn that some students not only aren't intuitively able to form a consistent model of assignment (one of the most basic requirements for understanding programming)--not even an incorrect but consistent one--but that they cannot do so even after a formal programming class. Some people, it appears, really can't learn to program. I guess what that says about me is that I have a high tolerance for nonsense. ;) The test (and answer key) is available at the paper's site, if you want to test yourself.
Due to a minor logic error which prevents FolderSyndication from publishing the XML in some cases, I've created a maintenance release. The package will automatically upgrade any previous versions, however, you should manually back up the .config file and any custom XSLT files you have added, as the installation process will overwrite or delete them.
Download Link (Note: This package will not install on Windows 2000 or previous due to its use of the LocalService account. To install on Windows 2000 or previous, use this package instead.)
If you have any questions, comments, or bug reports, please don't hesitate to contact me.
Announcing FolderSyndication 1.0. FolderSyndication is a tool that will watch folders and files for changes (new files, modified/renamed files, deletions, etc) and will publish those changes, for instance to an Atom feed (the default, although an RSS 2.0 feed is another provided option). If you don't like Atom or RSS 2.0, you can provide your own XSL transform to output whatever you want--Word document, raw XML, database update, whatever.
Features:
- Publish format is completely customizable through the use of standard XSLT files.
- Folders can be watched recursively, and notifications can be filtered by wildcard patterns.
- Publishing is performed at configurable intervals in order to not cause performance degradations during large file modifications (such as copying or deleting large numbers of files).
- Windows native FileSystemWatchers are used, meaning even a very large file tree can be watched efficiently. (Not yet tested against very high volumes of file changes.)
As with the other tools available on my website, FolderSyndication is licensed under a Creative Commons By Attribution license, meaning you are free to use and redistribute it as long as you give me credit as the original program author.
Download Link (Note: This package will not install on Windows 2000 or previous due to its use of the LocalService account. To install on Windows 2000 or previous, use this package instead.) Either package is about 400k in size.
If you have any questions, comments, or bug reports, please don't hesitate to contact me.
The other day I read in Wired (which probably means it's old news ;) about a "programming board game" invented by Igor Kholodov to teach kids the "basics of programming". It's called c-jump, and as Wired says,
The board game turns players into skiers who must race down a mountain in the quickest way possible. With each roll of the die, players must follow instructions that are similar to computer program codes. Using basic math, players have to figure out which paths are open to them and then decide the fastest way to the finish line. The trick, however, is learning which paths are open to you using only programmer jargon like "if (X==1)" then you can take the green path or "while (X<4) you can take the orange path," where X is the roll of the die.No offense to Mr. Kholodov, but I always have the same reaction whenever people talk about "teaching kids to program". That reaction is, more or less, confusion. I don't know that "teaching kids to program" is a particularly valuable thing to do, at least as most people seem to envision it. Teaching them the basics of programming, to me, involves teaching them to think logically and algorithmically, teaching them to construct mental models and extrapolate consequences, and to balance competing objectives. I don't see much use in teaching them what "x==1" means, or teaching them how to follow an if branch. The important thing is not to learn the syntax, but to learn the concepts. Not to learn how to follow an if branch (any idiot computer can do that), but when and why you might want to choose between two courses of action.
In fact, I think this concept of "teaching kids to program" meaning teaching them C-like syntax is symptomatic of a deeper problem in the industry; the idea that knowing how to program means only knowing the syntax for a language, being able to put together a file about which the compiler doesn't complain. Too many programs are constructed by trial-and-error, changing things semi-randomly until they work rather than understanding the system and considering the best method to use to solve the problem at hand.
Rote programming is not an advantageous skill; if you understand the concepts, you can pick up any language quite rapidly. Just as importantly, rote programming is something that can be effectively outsourced; there's no point in teaching your child a skill that will put them in the position of needing to be the lowest bidder to get a job. The advantageous skills are ones not unique to programming, which makes teaching them even more useful; the kid may choose to never write a single real program, after all, while mental modeling is a widely helpful skill. These skills are also the ones that tend to result in higher-paying or at least more satisfying jobs, something I think all of us want for our children. I applaud Mr. Kholodov's interest and his creativity, I just don't think this particular effort is as successful as it could be.
Several months ago, Roy Osherove posted a discussion of Defensive Event Publishing in .Net that discussed various problems with the "normal" methods of event publishing and raising in .Net. The naive programmer merely calls MyEvent(sender, eventArgs), never suspecting the minefield into which he or she is blithely strolling. Roy's post suggests several progressively more cautious methods of raising events to protect oneself against "bad" clients. At the time I commented that further improvements could be made, specifically to both avoid using Threadpool threads and to detect which callers are bad. I thought I'd finally get around to explaining what I meant and actually providing a solution I've used in the past.
First off, not using Threadpool threads. I'm really not a fan of using the Threadpool for any operation that I don't have absolute control over, because there's a limited number of them. The default number can be increased, but you can't make it infinite (and if you could, it would defeat the purpose of thread pooling anyway). IMO threadpool threads are useful for short, relatively deterministic operations which won't ever call any client code and which either will never fail, or will fail in such a way that you don't care or can't do anything about anyway. Raising events just doesn't fit those qualifications for me. So the solution is to not use threadpool threads; this is a fairly simple thing to do if you're at all familiar with .Net threading. Depending on your implementation, however, and definitely if you use the code I've posted at the end of this article, then there are a few caveats to watch for; I'll note them along the way.
The second way in which we can add to Roy's article is in detecting failed calls. His solution calls a OneWay async Invoke on the delegate; it's a fire-and-forget situation. Unfortunately, especially for an application that needs to stay up 24/7 for long periods of time, it may not be acceptable to just ignore failed calls; the app may want to clean up, or at least rid itself of the bad reference and let the GC pick it up. In order to do that, I use WaitHandles; each thread that I spawn for an individual delegate call will set a WaitHandle when it finishes. (Note that .Net events raised over Remoting automatically time out after a period of time. Using this method with non-remoted events would require additional code to detect timeouts, but would not require any additional code to detect clients that just don't exist anymore.) Here's one of our caveats: WaitHandle.WaitAll can only handle a certain number of handles; on the current .Net implementation (namely .Net 1.0 and 1.1 on Win32) that limit is 64 handles. Calling WaitHandle.WaitAll on > 64 handles will throw an exception. So, should you have more than 64 clients listening to the event, the code will automatically break them up into batches of 64 and wait on each batch sequentially. Another wrinkle is that WaitHandle.WaitAll isn't usable from STA threads--such as those used by Windows Forms--if you're waiting on more than one handle. This can be particularly tricky, as this means you probably can't raise an event using this code on your main Windows Forms UI thread. The code below doesn't handle this case (because our app wasn't a WinForm app and had no STA threads); if your code will be called from STA threads you will need to handle that situation (possibly by raising all events on a new thread).
The final caveat is that only the class that declares an event can modify that event (other than a simple += or -= to add/remove a listener). Thus you can't modify the delegate list to remove a specific listener except from the original class. In order to get around this, my utility function returns a new delegate list that has all of the "bad" clients removed. If your code needs better information about exactly which delegates were removed, you could add either an out param for the "bad" list, or a delegate called for bad clients, etc.
Using the code is fairly simple. The general case looks like this:
1 using System; 2 3 namespace EventTest 4 { 5 public delegate void MyEventHandler(object sender, EventArgs e); 6 7 public class EventRaiser 8 { 9 public event MyEventHandler MyEvent; 10 11 public void RaiseEvent() 12 { 13 MyEvent = (MyEventHandler)EventRemoter.RaiseRemotedEvent(MyEvent, this, EventArgs.Empty); 14 } 15 } 16 }
Relatively simple, aside from the need to cast the return value and the WaitHandle issues mentioned above.
The code for EventRemoter is available here. If you find it useful, or find a problem or just have a comment, please, let me know!
This code is covered by the same license as other items available from this blog, namely the Creative Commons' "By Attribution 2.0" license.
Addendum: After a brief conversation with someone who had recently asked me about this code, I added a static parameter to control the number of simultaneous threads that will be used by any one event raise, rather than using a magic number sprinkled through the code. The parameter defaults to 64 in order to be correct on Win32, but can be changed in either of two situations. If you want the code to use fewer threads (as the default version will spawn a lot of (very short-lived) threads when raising events to a lot of subscribers), then set the parameter lower. If you are using the code on a platform where WaitAll works with more than 64 handles, then you can set the parameter higher. The new version is at the same location linked above; enjoy!
Colin Coller has created a very nice plugin for VS.Net called CopySourceAsHtml that lets you create colorized text by copying source from VS.Net. It produces pure HTML code (not the stuff spat out by Word) using embedded stylesheets:
<style type="text/css">
.csharpcode
{
font-size: 10pt;
color: black;
font-family: Courier New , Courier, Monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0px; }
.rem { color: #008000; }
.kwrd { color: #0000ff; }
.str { color: #006080; }
.op { color: #0000c0; }
.preproc { color: #cc6633; }
.asp { background-color: #ffff00; }
.html { color: #800000; }
.attr { color: #ff0000; }
.alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0px;
}
.lnum { color: #606060; }
</style>
<div class="csharpcode">
<pre><span class="lnum"> 167: </span> <span class="rem">/// <summary></span></pre>
<pre><span class="lnum"> 168: </span> <span class="rem">/// Creates a new socket server object and optionally starts it listening.</span></pre>
<pre><span class="lnum"> 169: </span> <span class="rem">/// </summary></span></pre>
<pre><span class="lnum"> 170: </span> <span class="rem">/// <param name="name">The friendly name for this socket server.</param></span></pre>
<pre><span class="lnum"> 171: </span> <span class="rem">/// <param name="port">The port to listen on.</param></span></pre>
<pre><span class="lnum"> 172: </span> <span class="rem">/// <param name="startListening">Whether to immediately start listening, or wait for a <see cref="StartListening"/> call.</param></span></pre>
<pre><span class="lnum"> 173: </span> <span class="kwrd">public</span> SocketServer(<span class="kwrd">string</span> name, <span class="kwrd">int</span> port, <span class="kwrd">bool</span> startListening)</pre>
<pre><span class="lnum"> 174: </span> {</pre>
</div>Which turns out looking like this:
167: /// <summary>
168: /// Creates a new socket server object and optionally starts it listening.
169: /// </summary>
170: /// <param name="name">The friendly name for this socket server.</param>
171: /// <param name="port">The port to listen on.</param>
172: /// <param name="startListening">Whether to immediately start listening, or wait for a <see cref="StartListening"/> call.</param>
173: public SocketServer(string name, int port, bool startListening)
174: {
It's highly configurable and very cool, so if you intend to post code on the web, check it out!
Lately at work I've been dealing with a problematic socket server. The currently deployed version has something of a memory leak (to the tune of 140+MB/day), probably due to complications of incorrectly multithreading System.Net.Socket instances (note: they're not thread-safe).
Unfortunately, when I redid the socket server to lock all the sockets and other non-thread-safe resources, I ran into a deadlock. In chasing it down, I used Phil Haack's modification of Ian Griffith's TimedLock class. That enabled me to find where the deadlocks were, and eliminate them. This class is really a very clever tool, with one small problem: it was throwing exceptions on the production server. The test server ran fine for days at a time, loaded down as heavily as I could manage, but the production server locked inside of two hours every time. The first error in the log was always an ArgumentException thrown by the stack trace hashtable, saying that the object being inserted as the key was already in the hashtable.
After several days of debugging, and a few e-mails exchanged with Phil, he said the following to me:
If the object wasn't removed from the hashtable via the dispose method before the second lock is acquired, that could cause the error.
I started to write back, saying "But isn't the whole point of the locking that there is no way any other thread could acquire that lock until Dispose is called, thus calling Monitor.Exit and removing the object from the hashtable?", and then I was, as they say, enlightened. The sequence of events in the TimedLock runs like this:
TimedLock tl = TimedLock.Lock(o);
Monitor.TryEnter(o);
StackTraces.Add(o);
...
tl.Dispose();
Monitor.Exit(o);
StackTraces.Remove(o);
On a single-CPU machine (such as our test server), this code runs fine, I would guess, 99.99999% of the time. On a dual-cpu machine (such as the production server in question), however, it runs fine only 99% of the time. That 100th time, here's what happens...(assuming o is the same object in both threads)
Thread A Thread B
TimedLock tl = TimedLock.Lock(o);
Monitor.TryEnter(o);
StackTraces.Add(o); TimedLock tl = TimedLock.Lock(o);
... Monitor.TryEnter(o); // blocked
... ...waiting
... ...waiting
tl.Dispose(); ...waiting
Monitor.Exit(o); ...waiting
StackTraces.Add(o); //******
StackTraces.Remove(o);
The starred line is where the exception gets thrown. Textbook race condition -- if Thread B doesn't hit that Add() call between Thread A's calls to Monitor.Exit and StackTraces.Remove, then everything looks fine. But every once in a while (such as when processing a send and a receive simultaneously on a socket), it'll hit that tiny little target and blow the whole thing up.
What's worse is that as written, once that target has been hit, that object can't be successfully TimedLocked (even though the original lock has been released) until the TimedLock that hit the exception has been finalized. This is true even if you wrap the TimedLock in a using statement (because the exception will leave using() with a null reference, which it can't Dispose).
The fix? Simple -- swap the order of the Monitor.Exit() and StackTraces.Remove() calls. That ensures that the object will be removed from the hash table before any other thread can try to re-add it.
This all looks very cut and dry now that I've laid it out, but before anyone goes accusing Phil of not knowing his stuff, reread the subject of this post. Multithreading is hard. .Net (and other modern languages) do a good job of hiding some of the complexity; for most WinForms apps, for instance, threading is very easy as long as you remember to use InvokeRequired and Invoke. For something more complex, for instance a server app with multiple long-running threads that must access common resources, you need some help, and writing that help can be very difficult. It took me about 3 full days to find this bug, and all I have to say at the end is that if I weren't using a good helper class like TimedLock, it would have taken me much, much longer.
One other lesson I've (re)learned... always always always test multithreaded code on a multiprocessor machine, because it's so much easier to hit race conditions and other problems on that platform.
Slashdot posted a story about a sign in Cambridge, MA that poses a mathematical riddle which, when solved, leads to a website which poses yet another riddle which, when solved, ends up being a recruiting pitch for Google.
Google actually seems to be doing a lot of this--the current issue of Dr. Dobb's Journal has a leaflet in the middle which is several pages of strange or difficult (or both) questions and a postage-paid envelope. The envelope is addressed to Google, and encourages you to include your resume with your answers. This isn't the first time Google has used this particular billboard, either. And of course other companies have used similar, if not quite so difficult to solve, tricks as well.
I find this really interesting. Most companies act as if it's the potential employees' job to find and interest them, not the other way around. I don't live in any of the places they're hiring people like me for, but if I did I know this would pique my interest.
Task Scheduler, which comes bundled with Windows attempts to make automation of tasks effortless. Unfortunately, it is not very configurable and basic in what it is capable of. On UNIX and Linux systems, Cron is what is used for task scheduling. This scheduler is very configurable, and is capable of well more then its Windows counterpart.
This isn't actually true. I believe it used to be, though I'm not sure, but for years now the Windows Task Scheduler has been far more capable than most people realize out of the box--it just hides it well.
To set up a task that runs every 15 minutes, here are the steps:
- Start->Control Panel->Scheduled Tasks->Add Scheduled Task.
- Click Next.
- Select any program (we'll be replacing this so it doesn't matter) and hit Next.
- Name the task "MT Periodic Tasks".
- Select Perform This Task Daily and hit Next. Hit Next (accept the default start time/date).
- If prompted, enter your username and password (twice for the password) and hit Next.
- Check "Open advanced properties for this task" and hit Finish. The advanced properties will open.
- Change the Run: box to read "perl run-periodic-tasks".
- Change the Start In: box to the name of the directory where your run-periodic-tasks script is (for example C:\Inetpub\wwwroot\mt\tools).
- Select the Schedule tab and click Advanced. Pick today's date as the start date, and check Repeat Task. Set the Every boxes to whatever your repeat rate should be (for instance 15 and minutes). Check the "Duration" button, and set it to 23 hours and 59 minutes and click OK. This will run the task every day and repeat it every 15 minutes for 24 hours. At the end of the 24 hours it will be a new day, and the task will start over -- repeating every 15 minutes for another 24 hours. This part of the interface is especially unintuitive; somebody should make a new interface for Task Scheduler that actually makes sense to normal people. :-P
- Change the start time to 15 minutes from now and click OK. If you are prompted again for your username and password, put them in and hit OK.
Your task will now run every 15 minutes until you disable or delete it.
Another update to SharpTerminal: this one fixes the large blank spaces on the bottom and right sides of the GUI, as well as a minor startup bug where if you hadn't saved any default settings, and hit Connect without going to the Config tab, you'd get an error. Going to the Config tab and back fixed the problem, but now it shouldn't appear at all.
The GUI bug was an interesting one for me. The computer I write SharpTerminal on had the DPI setting (Display Properties, Settings, Advanced) set to Large (90DPI). So the GUI looked fine on that computer, but it turns out that .Net is smart enough to perform Automatic Control Scaling according to the difference between the developer's settings and the runtime settings. This works great when the developer's settings are Normal and the runtime settings are whatever; Windows Forms scales the GUI appropriately. Things get a little weird when the developer's settings are Large (or possible any non-Normal setting)--as you can see in the screenshot below, on a system set to Normal, the scaling doesn't quite work:
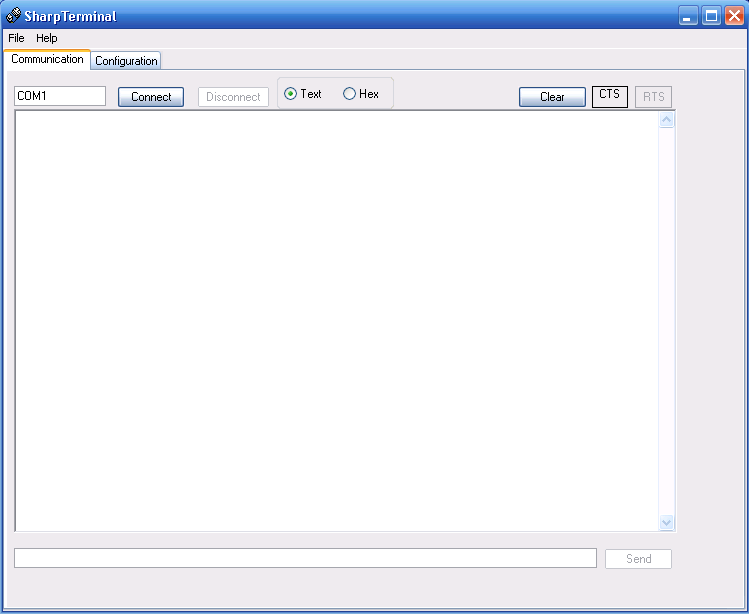
The solution turns out to be fairly convoluted. First, set the developer's computer to use Normal DPI settings and restart the PC. Next, open the solution in VS.Net and go to the code for the form with the issue. Look for a line that says this.AutoScaleBaseSize = new System.Drawing.Size(6, 15); in the Windows Form Designer generated code region, and change the values to 5, 13 (the default values for a Normal system). Open the form in designer mode. Things will likely be very screwed up (controls will run off the bottom and right sides). Fix them. Note that some controls--for instance, the Microsoft ActiveX Web Browser Control--will probably have to be removed and readded in order to work properly. Recompile and the app should look right.
Of course, probably the best idea is for developers to not use strange DPI sizes to develop UIs in the first place. :-P

{kind=link}